什么是链表
链表和数组一样,是一种线性的数据结构,由一个一个节点构成,节点中存放着数据,以及指向下一个或上一个节点的指针,通过指针,将节点链接在一起,构成整个链表结构。不同于数组,链表在内存中并不是连续的存储空间。
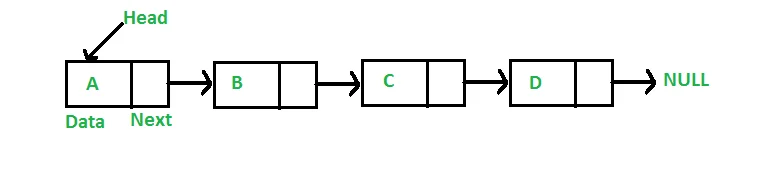
为什么要用链表?或者说链表有哪些优点
我们知道,数组是很方便的数据结构,但是数组有一些局限性。必须事先知道要分配多少内存空间。插入和移除是很耗费性能的操作,因为需要移动不止一个元素。
而链表,正好弥补了数组的缺点,链表是动态内存,不需要事先分配固定大小的空间,添加和删除元素,也只需要改变指针即可,不需要移动很多元素。
链表的缺点
当然,链表也有弊端。无法像数组一样随机访问,例如要访问第5个元素,是没办法直接访问的,只能遍历。每一个节点,需要额外的内存空间用来存储指向下一节点的指针。对缓存不友好,因为链表的内存空间并不一定是连续的。
链表怎样用代码表示,以及插入、删除、遍历操作
下面我们使用C#来描述一下链表
/// <summary>
/// 链表中的节点结构
/// </summary>
public class Node
{
public int data;
public Node next;
public Node (int data)
{
this.data = data;
}
}
public class Linkedlist
{
public Node head;
public Node tail;
/// <summary>
/// 插入一个节点
/// </summary>
/// <param name="data"></param>
public void InsertNode(int data)
{
Node newNode = new Node(data);
if(head == null)
{
head = newNode;
tail = newNode;
}
else
{
tail.next = newNode;
tail = newNode;
}
}
/// <summary>
/// 删除一个节点
/// </summary>
/// <param name="node"></param>
public void DeleteNode(Node node)
{
// 只有一个节点的情况
if(head == tail && head == node)
{
head = null;
tail = null;
}
else
{
Node prev = head;
Node opt = head.next;
while(opt != null)
{
// 如果当前检查的节点就是要删除的节点,
// 则用上一个节点,指向当前操作节点的下一个节点,
// 这样就把当前节点从链表中剔除了。
if(node == opt)
{
prev.next = opt.next;
break;
}
else
{
prev = opt;
opt = opt.next;
}
}
}
}
/// <summary>
/// 遍历整个链表,调试打印数据
/// </summary>
public void LoopDebug()
{
Node opt = head;
while(opt != null)
{
Debug.LogFormat("Data: {0}", opt.data);
opt = opt.next;
}
}
}
再深入一点点
我们上面介绍的,是单向链表,还有双向链表,就是每一个节点,即包含指向下一个节点的指针,又包含指向上一个节点的指针。看下面的代码。
/// <summary>
/// 双向链表中的节点结构
/// </summary>
public class Node
{
public int data;
public Node next;
public Node prev;
public Node (int data)
{
this.data = data;
}
}
双向链表在操作上和单向链表类似,只是在添加和删除操作时,要多考虑一个指向的问题。
注意和添加和删除函数中的代码变化
public class Linkedlist
{
public Node head;
public Node tail;
/// <summary>
/// 插入一个节点
/// </summary>
/// <param name="data"></param>
public void InsertNode(int data)
{
Node newNode = new Node(data);
if(head == null)
{
head = newNode;
tail = newNode;
}
else
{
newNode.prev = tail;
tail.next = newNode;
tail = newNode;
}
}
/// <summary>
/// 删除一个节点
/// </summary>
/// <param name="node"></param>
public void DeleteNode(Node node)
{
// 只有一个节点的情况
if(head == tail && head == node)
{
head = null;
tail = null;
}
else
{
Node prevNode = head;
Node optNode = head.next;
while(optNode != null)
{
if(node == optNode)
{
if(optNode.next != null)
{
optNode.next.prev = prevNode;
}
prevNode.next = optNode.next;
break;
}
else
{
prevNode = optNode;
optNode = optNode.next;
}
}
}
}
/// <summary>
/// 遍历整个链表,调试打印数据
/// </summary>
public void LoopDebug()
{
Node opt = head;
while(opt != null)
{
Debug.LogFormat("Data: {0}", opt.data);
opt = opt.next;
}
}
}
总结一下
链表是很常用的,当使用数组不能满足需求时,就可以向链表的方向考虑一下,或许会有解决思路。现在很多高级编程语言已经内置了可以动态改变的大小的数据结构,例如C#中的List,ArrayList等,Linkedlist 也有现成的实现。虽然如此,但是在一些特定的逻辑中,自己的逻辑实现可能更加灵活一些,这个要根据实际情况权衡。
好了,如果有什么问题,欢迎在下面留言交流噢~