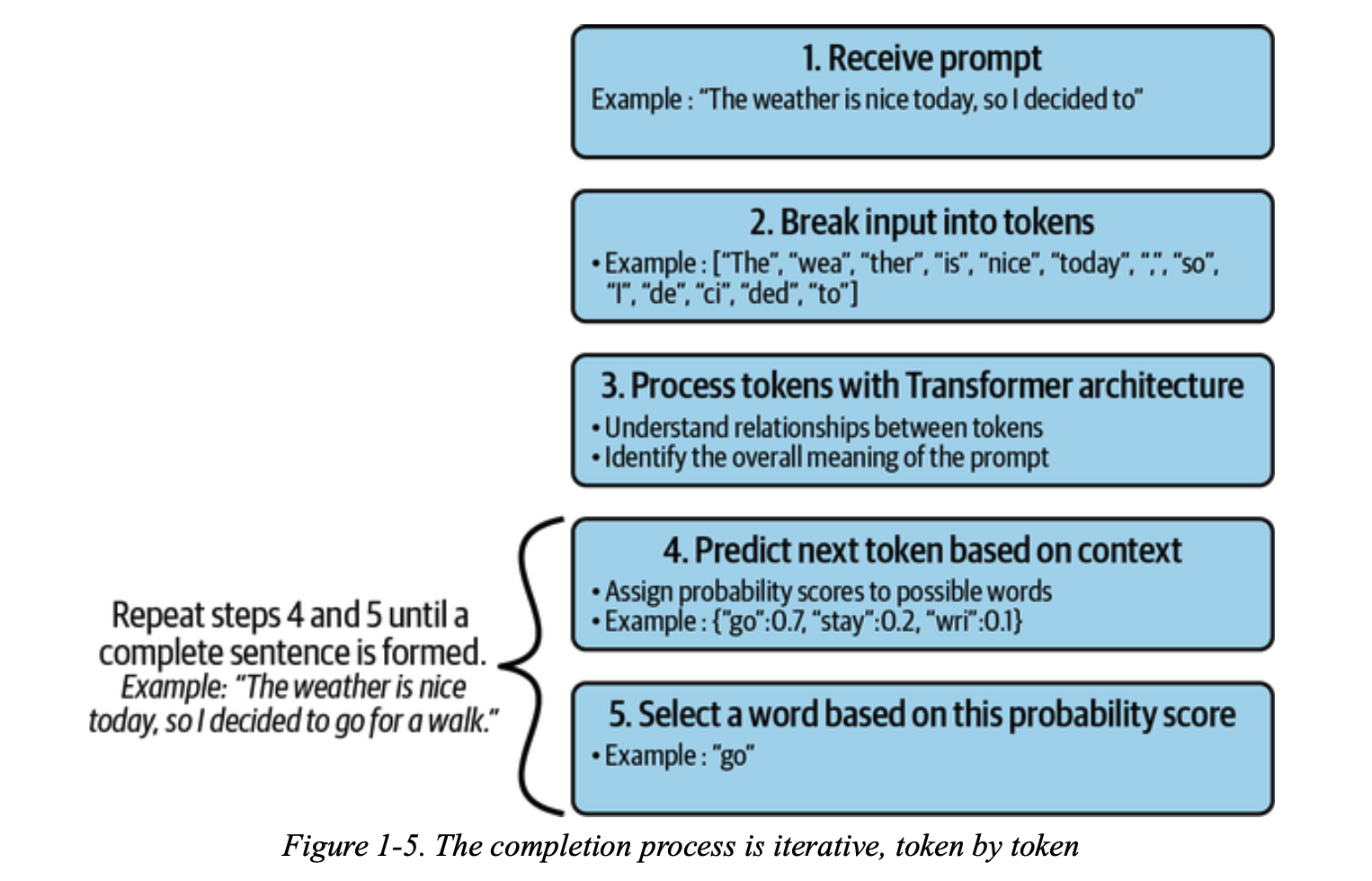
GPT 系列的 LLM 接收提示作为输入,然后生成文本。这个过程被称为文本补全。例如,提示可能是 “The weather is nice today, so I decided to”,而模型的输出可能是 “go for a walk”。您可能想知道 LLM 模型是如何根据输入提示构建输出文本的。正如你将看到的,这主要是一个概率问题。
在向 LLM 发送提示(prompt)时,LLM 会首先将输入内容分割成更小的片段(称为 “标记”)也就是 token。这些标记(token)代表单个单词、单词的一部分或空格和标点符号。例如,前面的提示可以这样分解: “the”、“wea”、“ther”、“is”、“nice”、“today”、","、“so”、“I”、“de”、“ci”、“ded”、“to”。每个语言模型 都有自己的标记符。在撰写本文时,GPT-4 标记符号生成器还不可用,但您可以测试 GPT-3 标记符号生成器。
从单词长度的角度来理解词块的经验法则是,100 个词块约等于英文文本中的 75 个单词。
借助前面介绍的注意力原则和 Transformer 架构,LLM 可以处理这些标记,并解释它们之间的关系和提示的整体含义。Transformer 架构允许模型有效识别文本中的关键信息和上下文。
要创建一个新句子,LLM 会根据提示上下文预测最有可能出现的词组。OpenAI 制作了两个版本的 GPT-4,上下文窗口分别为 8,192 个和 32,768 个。以前的递归模型很难处理长输入序列,与之不同的是,带有注意力机制的 Transformer 架构允许现代 LLM 将上下文作为一个整体来考虑。根据上下文,模型会为每个潜在的后续标记分配一个概率分数。然后,概率最高的标记被选为序列中的下一个标记。在我们的例子中,在 “The weather is nice today, so I decided to “之后,下一个最佳标记可能是 “go”。
然后重复这一过程,但现在的语境变成了 “The weather is nice today, so I decided to go”,这时先前预测的标记 “go"被添加到原始提示中。模型可能预测的第二个标记是 “for”。这个过程不断重复,直到形成一个完整的句子: “go for a walk”。这个过程依靠的是 LLM 从海量文本数据中学习下一个最有可能出现的单词的能力。